

The Internet: Under the Hood, Part 3
2021-10-01
Hopping on Out of Town
In part two we explored the Link layer of the TCP/ IP model as well as ethernet , the most common protocol therein. In this post, I'll be walking through the next layer up the model, the Internet layer, as well as the Internet Protocol (IP) .
Imagine for a second that our digital communications we were limited to LANs. Email wouldn't be quite as useful if you could alternatively walk a physical letter to someone's doorstep. Social media wouldn't be nearly as interesting if the various communities consisted of only your college campus, office, or (gasp) your family. Wikipedia wouldn't be nearly as rich with knowledge if the number of contributors was measured by the dozen rather than hundreds of thousands. This hypothetical does not describe our online experience today because the technology that resides at the Internet layer allows communication to transcend local communities.
The Internet Layer and IP
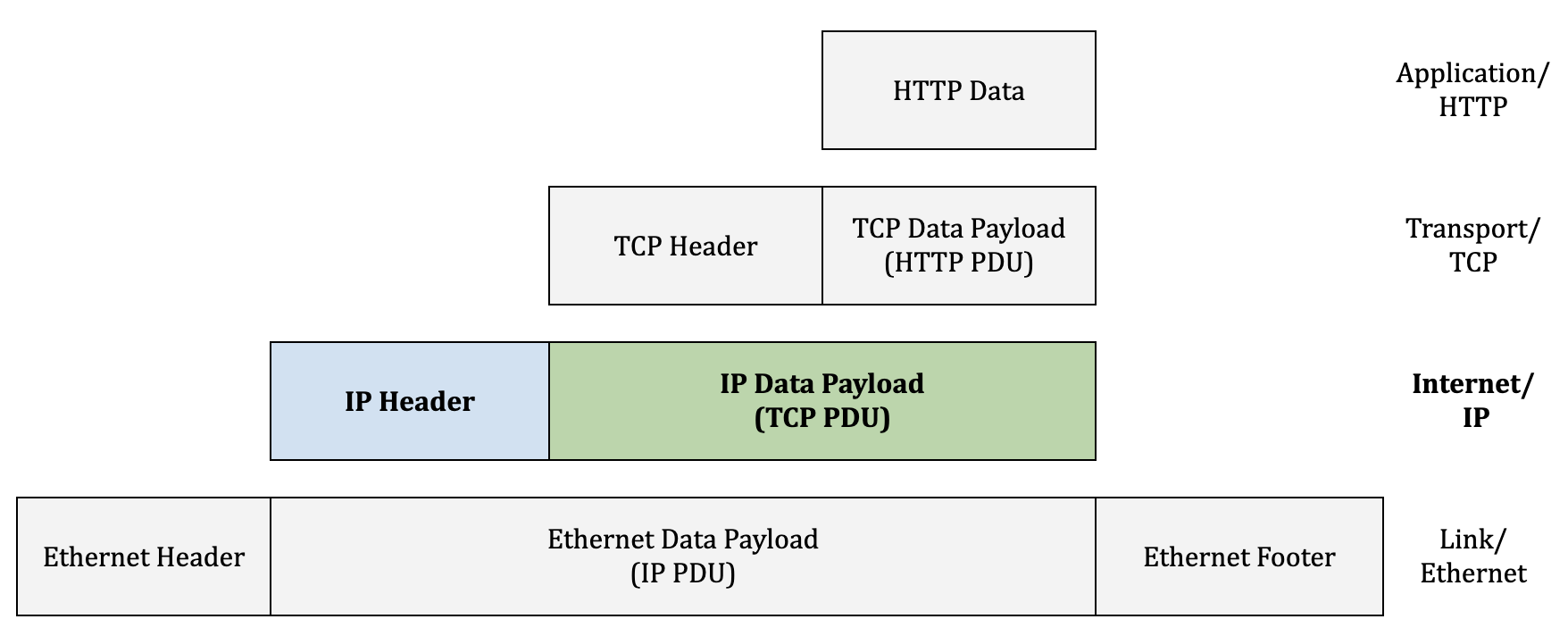
The primary function of protocols at the Network layer is to facilitate communication between hosts on different networks. The predominant protocol at this layer is IP and this post will focus on the two main characteristics of IP:
- Encapsulation of data into packets
- Routing capability via IP addressing
Note: there are two versions of IP currently in use today, IPv4 and IPv6, but I will be focusing on IPv4 because of its current prevalence. Any mention of "IP" is intended to reference IPv4 specifically.
PDU = "Packet "
IP groups data into PDUs called packets. Just like ethernet frames, IP packets encapsulate data from the the layer above and add on metadata in the form of headers to help that data reach its destination. The data payload of the packet usually consists of TCP segments or UDP datagrams (more on both in the next post in this series). Again, as with ethernet frames, the data in the IP Packet is in bits. The logical separation of those bits into header/footer fields and payload is determined by the set size of each field and the order within the packet.
One of the most interesting aspects of IP is fragmentation. This essentially means that IP is capable of splitting up a packet into multiple packets in order to accommodate the physical limitations of many different networks. When each fragment packet reaches the ultimate destination, IP reassembles the fragmented packets into a coherent message. In this way, IP data is independent of the constraints at the underlying Link layer.
Common metadata included in IP headers include:
- Source IP address and Destination IP address: more on these below
- ID, Flags & Fragment Offset: these fields are related to fragmentation. If the Transport layer PDU is too large to be sent as a single packet, it can be fragmented, sent as multiple packets, and then reassembled by the recipient.
- Protocol: indicates the protocol used (TCP, UDP, etc) for the data payload
- Checksum: used by routers to validate data. If there is an error, the packet is simply discarded!
- Time-To-Live(TTL): Essentially maximum hop count that helps avoid lost packets pinging around endlessly.
It's worth reiterating here that if a packet checksum fails while in transmission, the packet is simply discarded and IP does nothing to try and re-send the data. That function is left to the protocols at the Transport layer above.
IP Addressing
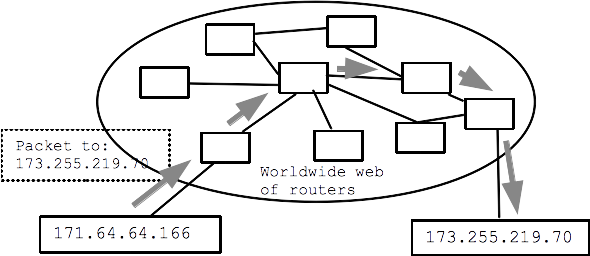
Now that you have an idea of what is included in an IP packet, it's time to revisit IP addressing. Unlike MAC addresses, IP addresses are logical as opposed to "burned-in" which mean means that a device can be assigned a new IP address when it joins a network. This logic also allows for IP addresss to be grouped in a hierarchy, allowing for efficient location look up of individual addresses.
IPv4 addresses are 32 bits in length and are divided into four sections of eight bits each. When converted to decimals, they look something like this: 106.16.230.25. The first section, 106 in our example, is known as the network identifier and does just that: identifies the network. The rest of the address is used to identify hosts that belong to the network.
With this system of addressing in place, when router A wants to forward an IP packet to a an address on a specific network, router A only needs to point the packet to the next router responsible for the network identifier, router B; Once the packet arrives at router B, router B takes care of the rest. This logic is what creates the hierarchical structure of the internet, and means that routers don't need to keep records of every single device within an addressable range. The idea of splitting a network into parts grouped by a network identifier, is known as sub-netting. In fact subnets can be split into smaller subnets, creating subsequent tiers in the hierarchy. This is what facilitates the scale of the internet.
Recall from part 2, that a data's journey from point A to point B is rarely, if ever, direct. An IP packet is likely to pass through a number of different routers on its journey and each segment of the journey is known as a hop. When an IP packet is received by a router, the router examines the destination IP address and matches it against a list of network addresses in its routing table. The matching network address will determine where in the network hierarchy the subnet exists. This will then be used to select the best route for the IP packet to travel.
Wrapping Up
In this post we discussed the Internet layer of the TCP/ IP model, the Internet Protocol and its unique characteristics of addressing and fragmentation. So our mental model now includes the mechanism for a message to travel outside its own network from one device to another. But what happens when that message arrives at its destination? How will the receiving device know what to do with it? Also, what can be done to introduce some reliability in our communications? These points will be addressed in the next post which will explore the Transport layer of the TCP/ IP model. Thanks for reading!