

The Internet: Under the Hood, Part 5
2021-10-05
Thus far in the series, we've covered the Link, Internet, and Transport layers of the TCP/ IP networking model. The last step is to explore the Application layer and the main protocol concerned with web development: HTTP.
HTTP is a broad topic so for this post we'll limit the discussion to the basics, including URLs, DNS, and the HTTP request/ response cycle. This post will not touch on security, the TLS protocol, or how to build stateful applications, I'll leave that to someone with more experience than I.
The Application Layer
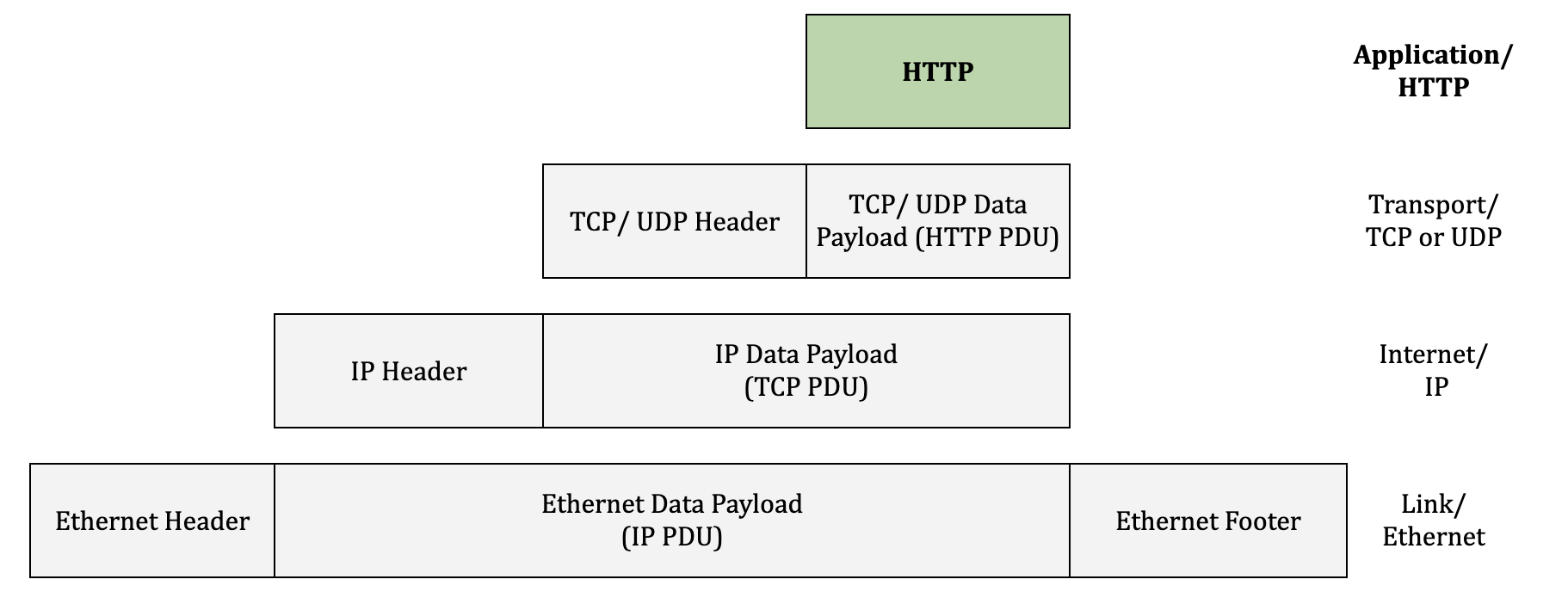
The application layer is the topmost layer of the TCP/ IP model. This layer does not represent the application itself, but rather a set of protocols that provide communications services to applications. Application layer protocols rely on the protocols at the layers below them to ensure that a message gets to where it is supposed to, and focus instead on the structure of that message and the data that it should contain.
Common application layer protocols include FTP (file sharing), SMTP (email), as well as HTTP (web).
HTTP
The Hypertext Transfer Protocol (HTTP) was developed by Tim Berners-Lee in 1989 and is a system of rules that provides uniformity to the way resources on the web are transferred between applications. These resources, which can be all manner of webpages, files, images, video, and even software, are transferred in the form of hypertext documents.
HTTP follows a simple model where a client makes a request to a server and waits for a response. As such, it's referred to as a request response protocol. Think of the request and the response as text messages, or strings, which follow a standard format that the other machine can understand. The most common type of client is a web browser which I am sure you're familiar with. Web browsers are responsible for generating HTTP requests and rendering HTTP responses into a form that people can understand. Servers are machines that house resources and are capable of handling client requests and responding back. The response a server sends back to the client contains data relevant to the request, if available.
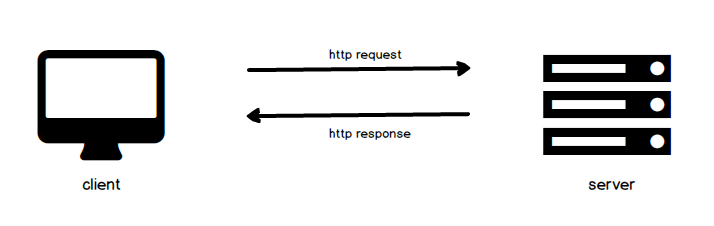
Before moving on, it's important to touch on the stateless nature of HTTP. Statelessness refers to the fact that each HTTP request or response is completely independent of the previous one. In other words the server does not need to hang on to information, or state, between requests. As a result, when a request breaks en route to the server, no part of the system has to do any cleanup. Thanks to this stateless property, HTTP is a said to be a resilient protocol, as well as a difficult protocol for building stateful applications.
URL
Above we touched on web browsers sending requests to servers, but how does a client find the right server? You already know this actually: the URL, or Uniform Resource Locator, aka the text that you input to the address bar of your browser.
Let's break down an example URL: https://theathletic.com:444/team/sf-giants/
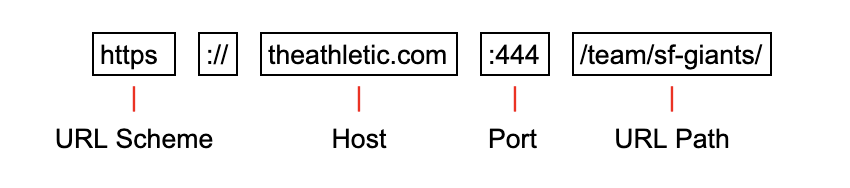
- URL Scheme: This field tells the web client how to access the resource. Scheme is a required field.
NOTE: the s in https stands for *secure * and indicates that messages are being encrypted with an additional protocol, usually Transportation Layer Security (TLS).
- Host: This field tells the client where the resource is located. Host is a required field.
- Port: This field is used to request a port other than the default port. (NOTE: 80 is the default port for HTTP, 443 for HTTPs). Port is optional.
- URL Path: This field shows what local resource is being requested. Path is optional
- Query String (not shown): This field is used to send data to the server. Optional.
But, you might be asking yourself, we just learned about the Internet Protocol and how it's unique characteristics (hierarchical, logical) allowed for efficient message routing between networks. How does this URL translate into an IP address???
DNS
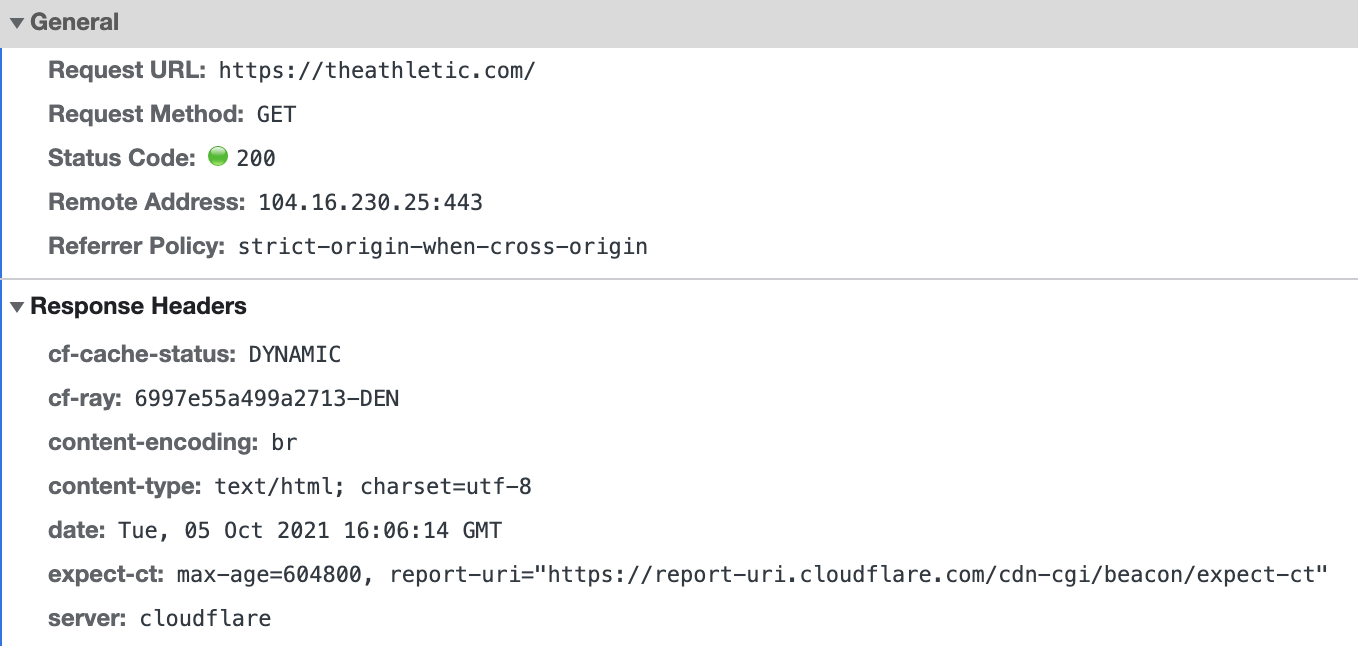
Domain Name System (DNS) is a distributed database which translates a domain name such as https://theathletic.com into its corresponding IP address 104.16.230.25, which is ultimately used to send a request to the server. From wikipedia:
The Domain Name System delegates the responsibility of assigning domain names and mapping those names to Internet resources by designating authoritative name servers for each domain. Network administrators may delegate authority over sub-domains of their allocated name space to other name servers. This mechanism provides distributed and fault-tolerant service and was designed to avoid a single large central database.
Basically there are many servers in the world that comprise the DNS system and no single machine contains the complete database. If a look up request reaches a DNS server which does not contain the requested domain name, the DNS server routes the request to another DNS server until it's found. Eventually the address will be located and the IP address will be used to complete the HTTP request.
Request Methods and HTTP Headers
Now, not every HTTP request is the same. Different requests are expected to achieve different results. Enter: HTTP request methods which tell the server what action to perform on a resource. The two most common request methods are GET and POST.
The GET method is the most used HTTP request method and is intended to retrieve a resource. When you click on a link for example, you are (in most cases) initiating a new GET request. Though there are exceptions, GET requests can generally be thought of as read-only operations.
POST requests are intended to send data to the server. For example, when you submit a form in a web browser, the browser is able to send the data to the server via a POST request. This form data is sent in the HTTP body, more on this below.
HTTP Headers allow the client and the server to send additional information during the request/ response cycle. Headers are colon-separated name-value pairs that are sent in plain text. An example of a request header is Connection: keep-alive which asks the server to maintain the connection even after it responds. Some examples of a response header are Content-type and Location which is used by the server when it needs to redirect the client to a new address.
Below are the required and optional components of HTTP requests and responses (assumes HTTP version 1.1):
Requests:
- Required: method, path, host
- Optional: parameters, all other headers, body
Responses:
- Required: status code (discussed below)
- Optional: headers and body
Status Codes
Every HTTP response is required to include a status code which is a three-digit number that signifies the status of a HTTP request. The most common status codes include the following:
- 200 - OK: the request was handled successfully
- 302 - Found: the requested resource has changed; usually results in a redirect
- 404 - Not Found: Resource cannot be found. Indicates an issue on the client side
- 500 - Internal Server Error: Indicate an issue on the server side
The Request/ Response Cycle
At this point we can tie everything that we've learned about the TCP/ IP model together to paint a picture of what happens under the hood during your daily web browsing. Below is a simplified example of a GET request:
- Enter a URL into your web browsers address bar:
- The browser creates an HTTP request which is encapsulated by the PDU of the Transport Layer (we'll use a TCP segment for this example).
The segment then arrives at the Internet layer, where the local DNS cache is consulted. If the address Is found, the IP packet will use the cached address. If the IP address isn't cached, a DNS request will be made to the Domain Name System to obtain the IP address for the domain.

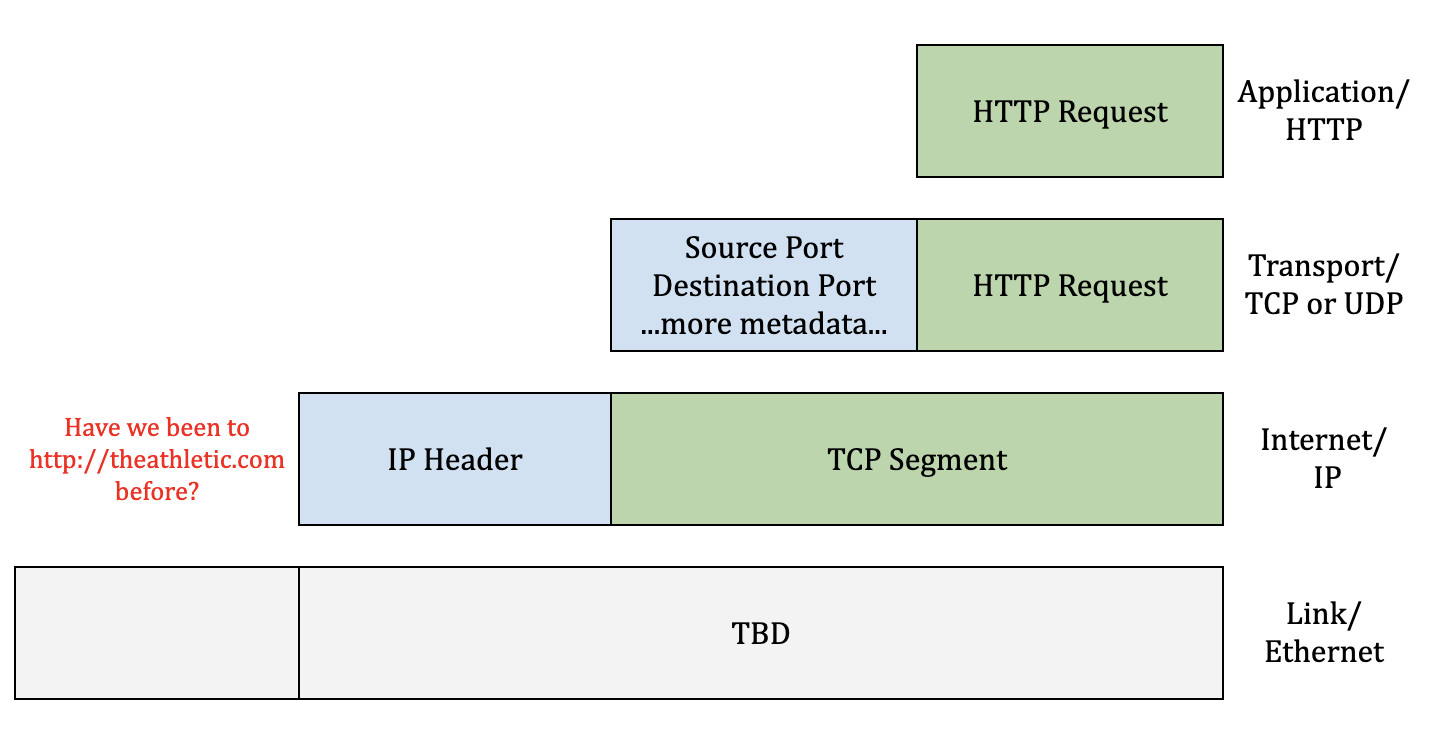
- With the server IP address in-hand, the packaged-up HTTP request then goes over the Internet where it is directed to the server with the matching IP address
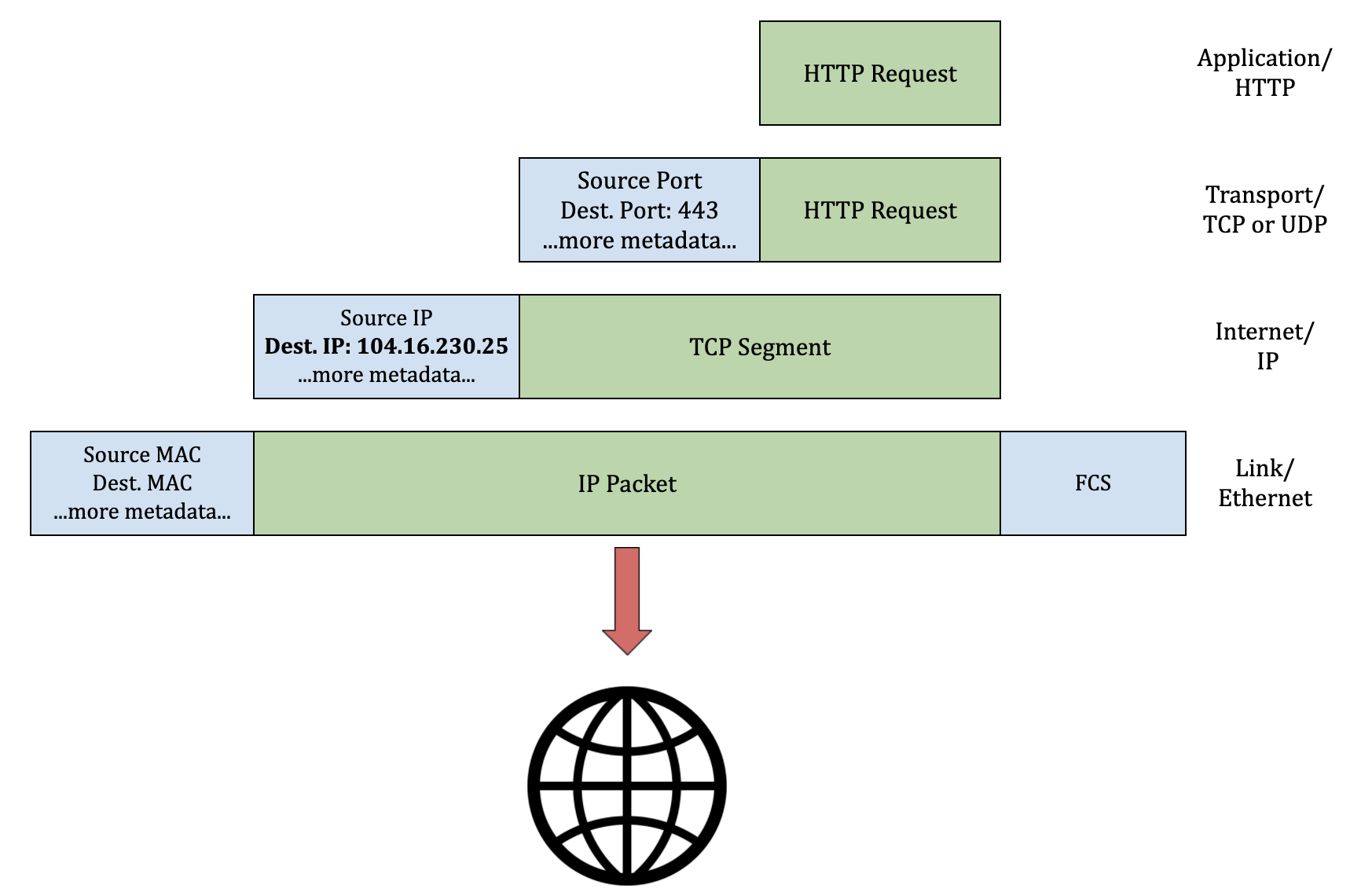
- The remote server accepts the request and sends a response over the Internet (using the same TCP/ IP model or something similar) back to your network interface which hands it to your browser (think TCP/ IP in reverse).
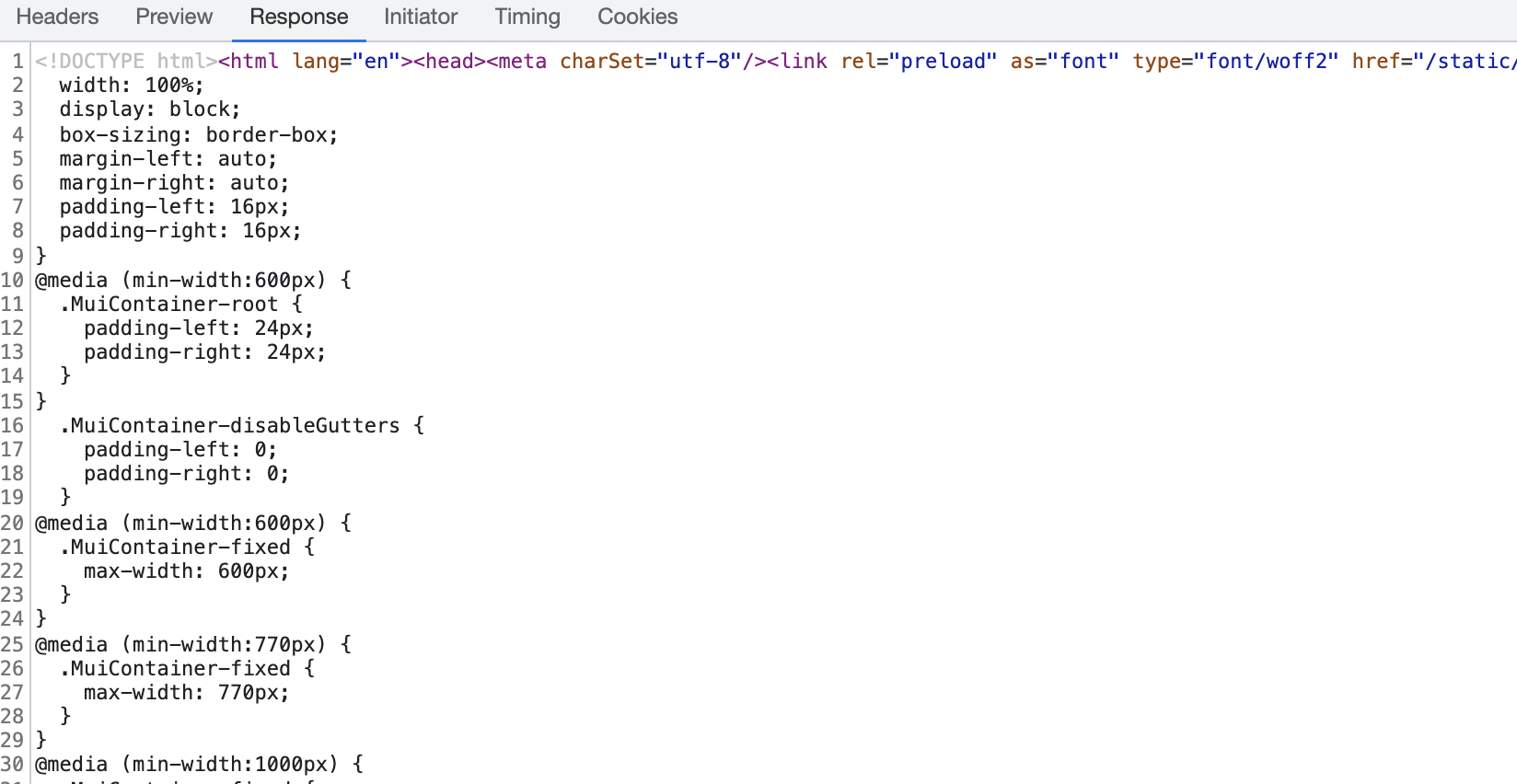
Here's a snippet of the (raw) response body, which consists of HTML, styling, and scripts:
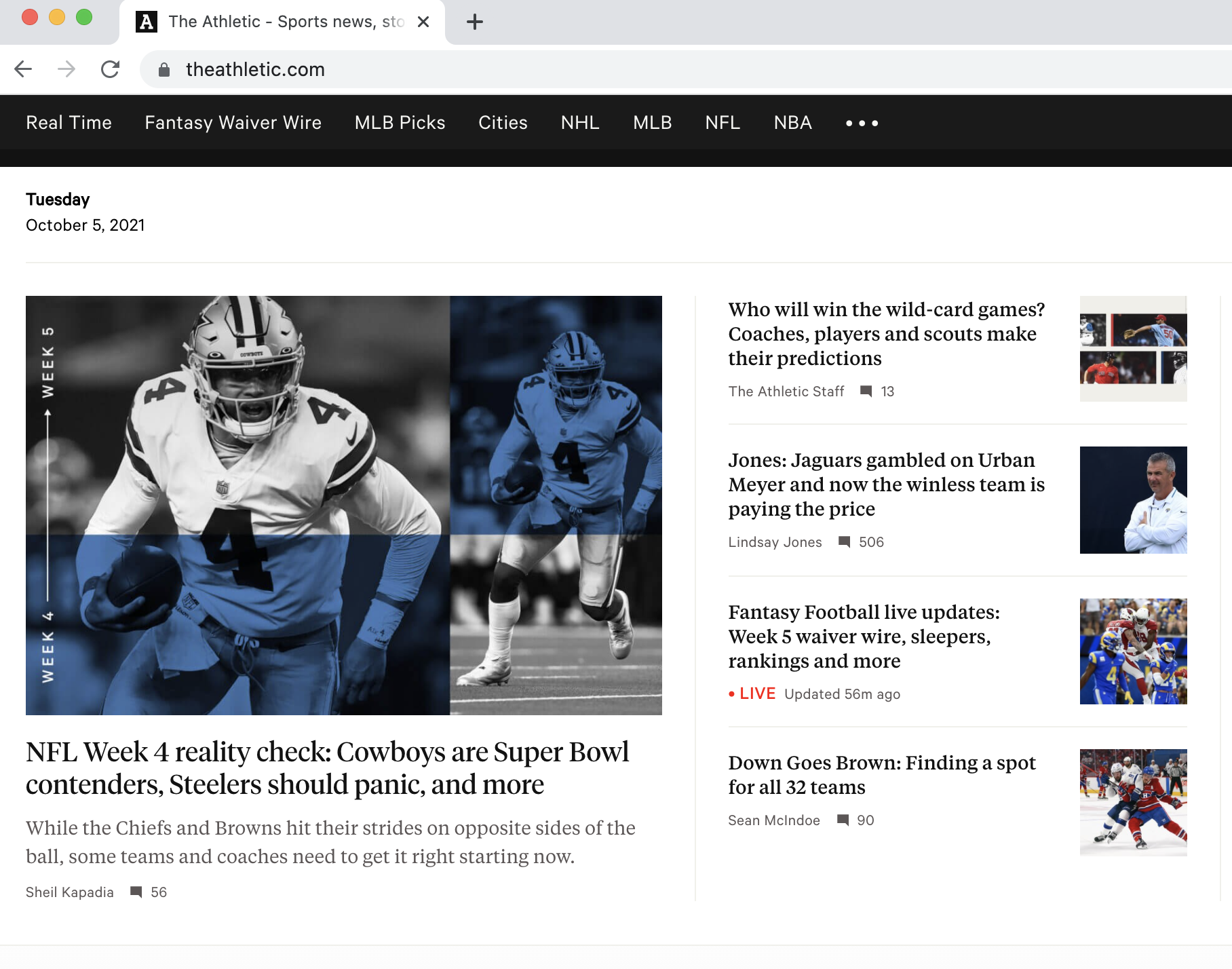
- Finally, the browser displays the response in the form of a webpage:
Wrapping Up
Whew, we've covered a lot of ground. I hope after reading this series of posts you have a solid mental model of networking as it pertains to web development and good idea of what exactly happens "under the hood" when you request a website. Thanks for reading!